
ai绘画怎么训练自己的模型?用Stable Diffusion训练出自己专属的人像模型
在数字艺术领域,AI绘画技术已经成为了一项引人注目的技术,让我们可以训练出独特的人像生成模型。稳定扩散(Stable Diffusion)是一个出色的工具,提供了多种模型训练方式,其中之一是Textual Inversion(Embedding),我们将在本文中介绍如何使用这种方法来创建专属的人像模型。

Textual Inversion(Embedding):小巧而强大
相较于其他模型训练方式,如“dream booth”,Textual Inversion(Embedding)的体积要小得多。在“dream booth”中,通常需要庞大的计算资源,而Textual Inversion则可以在Stable Diffusion内置的Web界面中轻松操作。
首先,您需要准备几十张照片,并将它们调整为512×512的尺寸,您可以使用birme网站来完成这个步骤。
接下来,打开Stable Diffusion界面,点击“训练”然后选择“建立嵌入”。在这一步,您需要填写模型的名称、初始化文字(这是在调用模型时使用的词语),以及每个标记的向量数(通常在6到10之间选择)。
点击“建立嵌入”按钮,系统将为您创建一个.pt格式的文件,用于存储模型的嵌入信息。
图像预处理和标签
接下来,您需要进行图像预处理和标签的添加。在这一步,您需要填写以下信息:
来源目录:这是您之前处理好的图片所在的目录,通常存储在Google Drive中。如果您的文件夹名为“xixiprincess_training”,则来源目录应填写为“/content/drive/MyDrive/xixiprincess_training”。
目标目录:这是保存打上标签的图片的文件夹,您可以在Google Drive中新建一个文件夹,例如“xixiprincess_training_input”。
此外,您还可以勾选底部的选项,包括“建立镜像副本”和“使用deepbooru生成说明文字”。然后点击“预处理”按钮,系统将为每张图片添加相应的标签,这些标签是对图片的文字描述,将用于训练模型。
模型训练
完成标签的添加后,您可以进行模型的训练。选择之前创建的“xixiprincess_training”文件,如果找不到该文件,可以点击右侧的蓝色按钮刷新一下页面。
在模型训练的设置中,指定资料集目录为刚才创建的“xixiprincess_training_input”,提示模板选择“style_filewords.txt”,其他设置保持默认。然后点击“训练嵌入”按钮。
系统会在每500步时展示训练模型的效果预览图。如果您对效果感到满意,可以点击“中止”来结束训练,否则可以继续让训练过程继续进行。一般来说,需要大约1万步左右才会出现较好的效果,而有些情况可能需要进行更多的训练,长达3万步。通常情况下,1万步的训练需要大约1个半小时。
使用训练好的模型
一旦训练完成,您可以在Stable Diffusion的Web界面中使用您的新模型。点击右上角的“产生”按钮下面的“Show Extra Networks”按钮,然后选择“textual inversion”。
在提示词输入框中,输入您想要生成的图片的描述,比如:“a girl reading a book in a library”。然后点击您刚刚训练的模型,系统会自动添加相应的提示词,然后点击“生成图片”按钮,即可看到生成的效果。
需要注意的是,Textual Inversion(Embedding)模型相对于其他方式,模型文件非常小,操作也相对简单,但效果可能不如“dream booth”明显,而且训练时间较长。综合来看,选择合适的模型训练方式取决于您的需求和时间投入。
在Stable Diffusion中,您可以探索多种方式来培养出独一无二的数字艺术作品,无论您是初学者还是经验丰富的艺术家,都能找到适合自己的方式来创造美妙的艺术作品。
最新推荐
-
excel怎么把一列数据拆分成几列 excel一列内容拆分成很多列
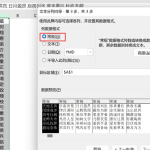
excel怎么把一列数据拆分成几列?在使用excel表格软件的过程中,用户可以通过使用excel强大的功能 […]
-
win7已达到计算机的连接数最大值怎么办 win7连接数达到最大值
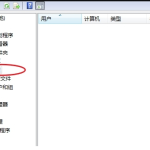
win7已达到计算机的连接数最大值怎么办?很多还在使用win7系统的用户都遇到过在打开计算机进行连接的时候 […]
-
window10插网线为什么识别不了 win10网线插着却显示无法识别网络
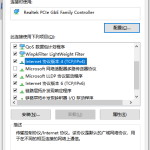
window10插网线为什么识别不了?很多用户在使用win10的过程中,都遇到过明明自己网线插着,但是网络 […]
-
win11每次打开软件都弹出是否允许怎么办 win11每次打开软件都要确认
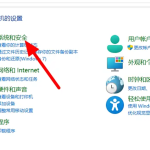
win11每次打开软件都弹出是否允许怎么办?在win11系统中,微软提高了安全性,在默认的功能中,每次用户 […]
-
win11打开文件安全警告怎么去掉 下载文件跳出文件安全警告
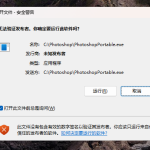
win11打开文件安全警告怎么去掉?很多刚开始使用win11系统的用户发现,在安装后下载文件,都会弹出警告 […]
-
nvidia控制面板拒绝访问怎么办 nvidia控制面板拒绝访问无法应用选定的设置win10
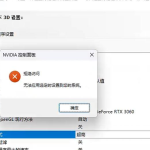
nvidia控制面板拒绝访问怎么办?在使用独显的过程中,用户可以通过显卡的的程序来进行图形的调整,比如英伟 […]
热门文章
excel怎么把一列数据拆分成几列 excel一列内容拆分成很多列
2win7已达到计算机的连接数最大值怎么办 win7连接数达到最大值
3window10插网线为什么识别不了 win10网线插着却显示无法识别网络
4win11每次打开软件都弹出是否允许怎么办 win11每次打开软件都要确认
5win11打开文件安全警告怎么去掉 下载文件跳出文件安全警告
6nvidia控制面板拒绝访问怎么办 nvidia控制面板拒绝访问无法应用选定的设置win10
7win11c盘拒绝访问怎么恢复权限 win11双击C盘提示拒绝访问
8罗技驱动设置开机启动教程分享
9win7设置电脑还原点怎么设置 win7设置系统还原点
10win10硬盘拒绝访问怎么解决 win10磁盘拒绝访问
随机推荐
专题工具排名 更多+




 闽公网安备 35052402000376号
闽公网安备 35052402000376号