
stable diffusion 生成人设图?stable diffusion角色设定图制作教程
你好,亲爱的读者们,我是电脑系统之家的小编。在这篇文章中,我们将向你介绍如何使用Stable Diffusion的方法来生成高质量的角色设定图。这个方法简单而高效,不需要繁琐的Textual Inversion或LoRA,让你能够轻松创作出惊艳的人物形象。

第一步:配合骨架图出图
首先,在txt2img中,使用具体的提示词来描述你想要的角色设定图。在这里,你可以运用自制的人物LoRA,搭配特定的服饰,比如:
(character sheet of the same exact Vallaria wearing black beret with golden rim and intricate [white|golden] robe and black cloak),
这个段落让AI明白你要创作的是一个角色设定稿。接下来,我们使用以下提示词来限定图像的背景,以确保AI不会过多地绘制背景干扰设定稿的质感:
(((white background))), (((simple studio background))), reference sheet,
然后,通过添加详细的修饰词来提升整体质感,例如:
((fantasy)), ((kind smiling)), real face, real skin, realistic face, realistic skin, detailed eyes, detailed facial features, detailed clothes features, detailed face and breast, beautiful eyes, detailed eyes, perfect body, perfect breasts, perfect face,
这些词汇将有助于确保生成图像的质量。最后,在lora参数中,你可以设置Vallaria的数值,例如:
<lora:VallariaV2:0.35>
这一步骤将为AI提供了足够的信息,使它能够按照你的要求生成图像。
第二步:放大并修脸
在第一步中生成的图像可能存在一些问题,特别是当角色的角度或面部表情不符合预期时。这时,我们可以采用以下方法进行修复。
首先,将生成的图像送入img2img,使用“send to img2img”按钮,并将图像放大至至少50%。在这个例子中,我们将图像扩展到1536X768,以便后续的面部修复。在“Resize mode”中,选择“Just resize(latent upscale)”,这样生成的图像可能会有些模糊,但这种模糊可以增加一种朦胧美的效果,根据个人需求来选择。
另外,不要忘记将txt2img中的ControlNet参数也重复设置在这里,以确保角色的姿势不会变化。
接下来,使用“Send to inpaint”将图像送入部分重绘。在这一步骤中,需要将图像中出现问题的脸部和服饰部分用遮罩标出,然后设置inpaint参数:
Mask content选择“original”,告诉AI你需要的结果与原图相似,以确保生成的脸部与整体画风一致。
Inpaint area选择“Only masked”。如果选择“Whole picture”,可能会导致脸部问题依然存在。
Denoising strength选择低于0.5,以防止人物的头部出现变形。
选择“Inpaint area”为“Only masked”的原因是,这会告诉AI你关心的是被遮罩的区域,AI会放大并修复这些区域,然后再将其缩小并合并到原图中。这一步将充分发挥擅长绘制头像和半身像的模组的特长。
最后,如果生成图像与原图不协调的部分,可以将生成图像再次输入img2img,以较低的Denoising strength输出,以获得更一致的结果。
通过这些方法,你可以轻松生成高质量的角色设定图,而无需复杂的技巧或多次尝试。稳定扩散的技术让创作过程更加高效和令人愉悦。希望这些方法对你的创作有所帮助!
最新推荐
-
excel怎么把一列数据拆分成几列 excel一列内容拆分成很多列
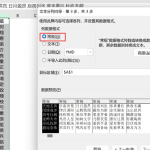
excel怎么把一列数据拆分成几列?在使用excel表格软件的过程中,用户可以通过使用excel强大的功能 […]
-
win7已达到计算机的连接数最大值怎么办 win7连接数达到最大值
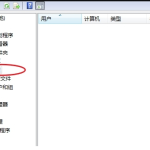
win7已达到计算机的连接数最大值怎么办?很多还在使用win7系统的用户都遇到过在打开计算机进行连接的时候 […]
-
window10插网线为什么识别不了 win10网线插着却显示无法识别网络
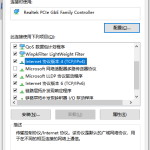
window10插网线为什么识别不了?很多用户在使用win10的过程中,都遇到过明明自己网线插着,但是网络 […]
-
win11每次打开软件都弹出是否允许怎么办 win11每次打开软件都要确认
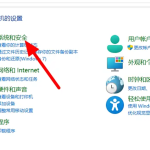
win11每次打开软件都弹出是否允许怎么办?在win11系统中,微软提高了安全性,在默认的功能中,每次用户 […]
-
win11打开文件安全警告怎么去掉 下载文件跳出文件安全警告
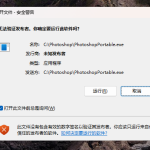
win11打开文件安全警告怎么去掉?很多刚开始使用win11系统的用户发现,在安装后下载文件,都会弹出警告 […]
-
nvidia控制面板拒绝访问怎么办 nvidia控制面板拒绝访问无法应用选定的设置win10
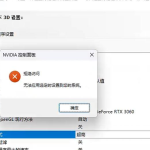
nvidia控制面板拒绝访问怎么办?在使用独显的过程中,用户可以通过显卡的的程序来进行图形的调整,比如英伟 […]
热门文章
excel怎么把一列数据拆分成几列 excel一列内容拆分成很多列
2win7已达到计算机的连接数最大值怎么办 win7连接数达到最大值
3window10插网线为什么识别不了 win10网线插着却显示无法识别网络
4win11每次打开软件都弹出是否允许怎么办 win11每次打开软件都要确认
5win11打开文件安全警告怎么去掉 下载文件跳出文件安全警告
6nvidia控制面板拒绝访问怎么办 nvidia控制面板拒绝访问无法应用选定的设置win10
7win11c盘拒绝访问怎么恢复权限 win11双击C盘提示拒绝访问
8罗技驱动设置开机启动教程分享
9win7设置电脑还原点怎么设置 win7设置系统还原点
10win10硬盘拒绝访问怎么解决 win10磁盘拒绝访问
随机推荐
专题工具排名 更多+




 闽公网安备 35052402000376号
闽公网安备 35052402000376号