
stable diffusion lora模型的原理
lora模型的原理是基于低秩适应技术,通过对cross-attention layers进行更改来加速大型模型的训练。在模型训练过程中,lora允许您更轻松地针对不同的概念进行模型训练,例如角色或特定的风格。
使用lora模型进行训练的步骤如下:
准备数据集:首先,您需要准备用于训练的数据集。这可以是文本、图像或其他类型的数据。
构建模型:接下来,您需要构建一个lora模型。lora模型是基于stable diffusion模型的小型版本,对cross-attention layers进行了更改。您可以使用现有的stable diffusion模型作为基础,并对其进行适当的修改。
训练模型:使用准备好的数据集和构建的lora模型,开始训练模型。您可以使用标准的训练算法,如反向传播算法,来优化模型的参数。
微调扩散模型:一旦lora模型训练完成,您可以使用低秩适应技术对扩散模型进行微调。这可以帮助您更好地适应不同的概念和样式。
导出模型:完成微调后,您可以将经过训练和微调的lora模型导出,并供其他人使用。导出的模型文件大小一般在2-500MB之间,相比于原始的checkpoint模型大大减小。
通过使用lora模型,您可以更高效地训练和微调扩散模型,以适应不同的概念和样式。这为模型的应用和推广提供了更大的灵活性和便利性。
结论
lora是一种在消耗更少内存的情况下加速大型模型训练的训练方法。它允许您使用低秩适应技术来快速微调扩散模型,以适应不同的概念和样式。lora模型相对于原始的checkpoint模型体积更小,文件大小一般在2-500MB之间。通过使用lora模型,您可以更高效地训练和微调模型,并将其导出供其他人使用。这为模型的应用和推广提供了更大的灵活性和便利性。
最新推荐
-
excel怎么把一列数据拆分成几列 excel一列内容拆分成很多列
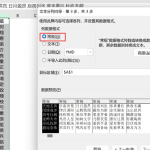
excel怎么把一列数据拆分成几列?在使用excel表格软件的过程中,用户可以通过使用excel强大的功能 […]
-
win7已达到计算机的连接数最大值怎么办 win7连接数达到最大值
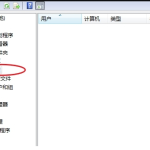
win7已达到计算机的连接数最大值怎么办?很多还在使用win7系统的用户都遇到过在打开计算机进行连接的时候 […]
-
window10插网线为什么识别不了 win10网线插着却显示无法识别网络
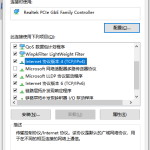
window10插网线为什么识别不了?很多用户在使用win10的过程中,都遇到过明明自己网线插着,但是网络 […]
-
win11每次打开软件都弹出是否允许怎么办 win11每次打开软件都要确认
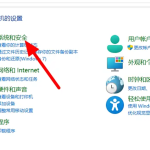
win11每次打开软件都弹出是否允许怎么办?在win11系统中,微软提高了安全性,在默认的功能中,每次用户 […]
-
win11打开文件安全警告怎么去掉 下载文件跳出文件安全警告
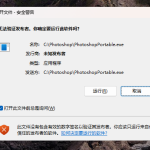
win11打开文件安全警告怎么去掉?很多刚开始使用win11系统的用户发现,在安装后下载文件,都会弹出警告 […]
-
nvidia控制面板拒绝访问怎么办 nvidia控制面板拒绝访问无法应用选定的设置win10
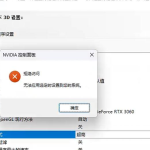
nvidia控制面板拒绝访问怎么办?在使用独显的过程中,用户可以通过显卡的的程序来进行图形的调整,比如英伟 […]
热门文章
excel怎么把一列数据拆分成几列 excel一列内容拆分成很多列
2win7已达到计算机的连接数最大值怎么办 win7连接数达到最大值
3window10插网线为什么识别不了 win10网线插着却显示无法识别网络
4win11每次打开软件都弹出是否允许怎么办 win11每次打开软件都要确认
5win11打开文件安全警告怎么去掉 下载文件跳出文件安全警告
6nvidia控制面板拒绝访问怎么办 nvidia控制面板拒绝访问无法应用选定的设置win10
7win11c盘拒绝访问怎么恢复权限 win11双击C盘提示拒绝访问
8罗技驱动设置开机启动教程分享
9win7设置电脑还原点怎么设置 win7设置系统还原点
10win10硬盘拒绝访问怎么解决 win10磁盘拒绝访问
随机推荐
专题工具排名 更多+




 闽公网安备 35052402000376号
闽公网安备 35052402000376号