
stablediffusion训练模型的步骤

取得高品质图片
为了训练稳定扩散模型,我们需要准备至少10张高品质的图片。重要的是图片的质量而不是数量。由于我们要训练的是单一人物且风格固定的模型,所以图片不应该有复杂的背景或其他无关人物。
你可以通过右键点击下载网络图片,但如果需要下载大量图片,我建议使用Imgrd Grabber或Hydrus Network。
在这里,我准备了33张由Hara绘制的斯卡萨哈的图片。
裁切图片
下载图片后,我们需要将训练图片裁切成512×512像素的大小。你可以选择使用SD WebUI自动裁切,或者手动裁切。
自动裁切
裁切图片不需要使用显卡计算。
将要裁切的图片放置在同一个目录下,例如/home/user/桌面/input。
打开SD WebUI,进入Train → Preprocess images页面。
在第一个字段”Source directory”中填写原始图片的路径。
在第二个字段”Destination directory”中填写输出路径,例如/home/user/桌面/cropped。
将宽度和高度设置为512×512。
点击”Preprocess”按钮,图片将自动裁切。之后,你可以删除原始图片,只保留裁切后的图片。
手动裁切
手动裁切图片的原因是为了避免重要的部分被裁掉。
安装修图软件GIMP,点击”文件”→”添加512×512像素的项目”。
使用油漆桶工具将画布涂成白色。
将图片拖曳到画布上,成为新的图层。
点击”工具”→”变形工具”→”缩放”,缩放图片使其符合画布大小,然后按Enter键。
点击”文件”→”导出”,将图片导出为png格式。
为了加快后续图片的处理速度,点击右下角的删除图层按钮,然后再拖入新的图片,重复上述操作。
将裁切后的33张Hara绘制的斯卡萨哈的图片统一放置到名为”raw”的目录中。
预先给图片上提示词
接下来,我们需要为图片预先添加提示词,这样AI才知道要学习哪些内容。
启动SD WebUI,进入Train页面。
进入Preprocess页面,将裁切后的图片的路径填入”Source”字段,将处理后的图片输出路径填入”Destination”字段。
勾选”Create Flipped Copies”,以创建翻转图片来增加训练数据量。
如果要训练真实图片的模型,勾选”Use BLIP for caption”;如果要训练动漫人物的模型,勾选”Use DeepBooru for caption”。
点击”Preprocess”按钮,几分钟后处理完成。输出目录中将包含每张图片对应的提示词txt文件。
打开txt文件,删除你认为与训练无关的特征,例如”2girls”这类过于笼统的提示词。
至此,训练数据准备完成。
最新推荐
-
excel怎么把一列数据拆分成几列 excel一列内容拆分成很多列
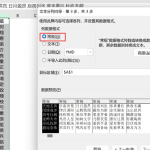
excel怎么把一列数据拆分成几列?在使用excel表格软件的过程中,用户可以通过使用excel强大的功能 […]
-
win7已达到计算机的连接数最大值怎么办 win7连接数达到最大值
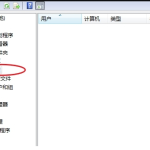
win7已达到计算机的连接数最大值怎么办?很多还在使用win7系统的用户都遇到过在打开计算机进行连接的时候 […]
-
window10插网线为什么识别不了 win10网线插着却显示无法识别网络
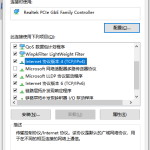
window10插网线为什么识别不了?很多用户在使用win10的过程中,都遇到过明明自己网线插着,但是网络 […]
-
win11每次打开软件都弹出是否允许怎么办 win11每次打开软件都要确认
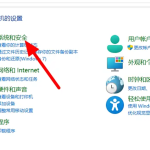
win11每次打开软件都弹出是否允许怎么办?在win11系统中,微软提高了安全性,在默认的功能中,每次用户 […]
-
win11打开文件安全警告怎么去掉 下载文件跳出文件安全警告
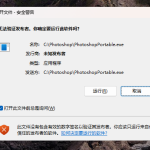
win11打开文件安全警告怎么去掉?很多刚开始使用win11系统的用户发现,在安装后下载文件,都会弹出警告 […]
-
nvidia控制面板拒绝访问怎么办 nvidia控制面板拒绝访问无法应用选定的设置win10
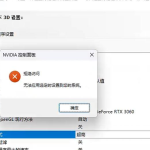
nvidia控制面板拒绝访问怎么办?在使用独显的过程中,用户可以通过显卡的的程序来进行图形的调整,比如英伟 […]
热门文章
excel怎么把一列数据拆分成几列 excel一列内容拆分成很多列
2win7已达到计算机的连接数最大值怎么办 win7连接数达到最大值
3window10插网线为什么识别不了 win10网线插着却显示无法识别网络
4win11每次打开软件都弹出是否允许怎么办 win11每次打开软件都要确认
5win11打开文件安全警告怎么去掉 下载文件跳出文件安全警告
6nvidia控制面板拒绝访问怎么办 nvidia控制面板拒绝访问无法应用选定的设置win10
7win11c盘拒绝访问怎么恢复权限 win11双击C盘提示拒绝访问
8罗技驱动设置开机启动教程分享
9win7设置电脑还原点怎么设置 win7设置系统还原点
10win10硬盘拒绝访问怎么解决 win10磁盘拒绝访问
随机推荐
专题工具排名 更多+




 闽公网安备 35052402000376号
闽公网安备 35052402000376号