
打造AI虚拟数字人,Stable Diffusion+Sadtalker教程
电脑系统之家为您带来了一篇关于如何使用Stable Diffusion和Sadtalker结合的教程。Stable Diffusion是一个能够根据文本描述生成高质量图片的深度学习模型,而Sadtalker则是一个能够根据图片和音频生成视频的开源项目。通过将这两个工具结合起来,我们可以实现从文本到视频的生成。

准备工作
在开始之前,您需要准备以下内容:
一台安装了Windows系统的电脑,最好有一块至少8GB显存的NVIDIA或AMD显卡
Stable Diffusion的代码和模型文件,可以从这里下载
Sadtalker的代码和模型文件,可以从这里下载
一个文本编辑器,例如Notepad++或Visual Studio Code
一个音频编辑器,例如Audacity或Adobe Audition
一个视频播放器,例如VLC或Windows Media Player
步骤一:生成图片
首先,我们需要使用Stable Diffusion根据我们想要的文本描述生成一张图片。我们可以使用Stable Diffusion Online网站来快速实现这个功能,也可以在本地运行Stable Diffusion的代码。
使用Stable Diffusion Online网站
打开浏览器,访问https://stablediffusionweb.com/
在输入框中输入你想要生成图片的文本描述,例如“一个穿着红色连衣裙的女孩在草地上跳舞”
点击Generate按钮,等待几秒钟,就可以看到生成的图片
点击Download按钮,将图片保存到你的电脑上
在本地运行Stable Diffusion的代码
打开命令行窗口,进入Stable Diffusion的代码目录
输入以下命令,安装所需的依赖包:pip install -r requirements.txt
输入以下命令,下载预训练的模型文件:python download_model.py
输入以下命令,根据你想要生成图片的文本描述生成一张图片,并保存到output文件夹中:python generate.py --prompt "一个穿着红色连衣裙的女孩在草地上跳舞" --output output/girl.jpg
步骤二:录制音频(续)
在上一步骤中,我们已经介绍了如何录制音频。这里我们将继续介绍如何使用Adobe Audition录制音频。
使用Adobe Audition录制音频(续)
点击菜单栏中的文件-新建-音频文件
在弹出的对话框中输入文件名,例如girl,选择采样率为44100 Hz,通道为单声道,格式为MP3
点击确定按钮,创建一个新的音频文件
点击红色的录音按钮,开始录制你想要说的话,例如“你好,我是一个爱跳舞的女孩”
点击空格键,结束录制
点击菜单栏中的文件-保存
在弹出的对话框中选择保存位置,例如output文件夹
步骤三:生成视频
最后,我们需要使用Sadtalker将我们生成的图片和音频合成为一个视频。我们可以在本地运行Sadtalker的代码来实现这个功能。
在本地运行Sadtalker的代码
打开命令行窗口,进入Sadtalker的代码目录
输入以下命令,安装所需的依赖包:pip install -r requirements.txt
输入以下命令,下载预训练的模型文件:python download_model.py
输入以下命令,根据我们生成的图片和音频生成一个视频,并保存到output文件夹中:python generate.py --image output/girl.jpg --audio output/girl.mp3 --output output/girl.mp4
结语
恭喜您,您已经完成了使用Stable Diffusion和Sadtalker结合起来,实现从文本到视频的生成的教程。您可以在output文件夹中找到您生成的视频,并用任何视频播放器观看它。您也可以尝试用不同的文本描述和音频来生成不同的视频。希望您能享受这个有趣的创作过程,并发挥您的想象力和创造力。
最新推荐
-
excel怎么把一列数据拆分成几列 excel一列内容拆分成很多列
excel怎么把一列数据拆分成几列?在使用excel表格软件的过程中,用户可以通过使用excel强大的功能 […]
-
win7已达到计算机的连接数最大值怎么办 win7连接数达到最大值
win7已达到计算机的连接数最大值怎么办?很多还在使用win7系统的用户都遇到过在打开计算机进行连接的时候 […]
-
window10插网线为什么识别不了 win10网线插着却显示无法识别网络
window10插网线为什么识别不了?很多用户在使用win10的过程中,都遇到过明明自己网线插着,但是网络 […]
-
win11每次打开软件都弹出是否允许怎么办 win11每次打开软件都要确认
win11每次打开软件都弹出是否允许怎么办?在win11系统中,微软提高了安全性,在默认的功能中,每次用户 […]
-
win11打开文件安全警告怎么去掉 下载文件跳出文件安全警告
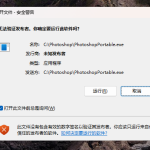
win11打开文件安全警告怎么去掉?很多刚开始使用win11系统的用户发现,在安装后下载文件,都会弹出警告 […]
-
nvidia控制面板拒绝访问怎么办 nvidia控制面板拒绝访问无法应用选定的设置win10
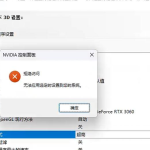
nvidia控制面板拒绝访问怎么办?在使用独显的过程中,用户可以通过显卡的的程序来进行图形的调整,比如英伟 […]
热门文章
excel怎么把一列数据拆分成几列 excel一列内容拆分成很多列
2win7已达到计算机的连接数最大值怎么办 win7连接数达到最大值
3window10插网线为什么识别不了 win10网线插着却显示无法识别网络
4win11每次打开软件都弹出是否允许怎么办 win11每次打开软件都要确认
5win11打开文件安全警告怎么去掉 下载文件跳出文件安全警告
6nvidia控制面板拒绝访问怎么办 nvidia控制面板拒绝访问无法应用选定的设置win10
7win11c盘拒绝访问怎么恢复权限 win11双击C盘提示拒绝访问
8罗技驱动设置开机启动教程分享
9win7设置电脑还原点怎么设置 win7设置系统还原点
10win10硬盘拒绝访问怎么解决 win10磁盘拒绝访问
随机推荐
专题工具排名 更多+




 闽公网安备 35052402000376号
闽公网安备 35052402000376号